00_モデルの構築と訓練
学ぶべき項目は以下
-
TensorFlow2.0 以降を使用する。
- tutorial1
- モデルの作成例
- TensorFlow を使用して機械学習(ML)モデルの構築、コンパイル、訓練を行う。
- データを前処理してモデルで使用できるようにする。
- モデルを使用して結果を予測する。
- 複数の層で構成されるシーケンスモデルを構築する。
- 二項分類のモデルを構築して訓練する。
- 多項分類のモデルを構築して訓練する。
- tutorial2
- この章は長いので別ページに分ける
- 事前訓練されたモデルを使用する(転移学習)。
- 事前訓練されたモデルから機能を抽出する。
- モデルへの入力が適切な形状で行われるようにする。
- テストデータをニューラルネットワークの入力の形状に合わせたものにする。
- ニューラル ネットワークの出力データを、テストデータで指定された入力の形状に合わせたものにする。
-
- データの一括読み込みについて理解している
- コールバックを使用して、訓練サイクルの終了を呼び出す。
- 複数のソースのデータセットを使用する。
- 複数のフォーマット(json や csv など)のデータセットを使用する。
- tf.data.datasets のデータセットを使用する。
-
- 訓練済みモデルのプロットの損失と精度を確認する。
- 拡張やドロップアウトなどの過剰適合を避けるための戦略を割り出す。
tutorial1
- TensorFlow を使用して機械学習(ML)モデルの構築、コンパイル、訓練を行う。
- データを前処理してモデルで使用できるようにする。
- モデルを使用して結果を予測する。
"""🌟 モデルの構築
"""
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
"""🌟 モデルのコンパイル
"""
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
"""🌟 モデルの訓練
"""
model.fit(train_images, train_labels, epochs=5)
"""🌟 モデルの正解率の評価
"""
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('Test accuracy:', test_acc)
"""
🌟 予測
- 入力には入力の配列を入れる必要がある。
- 多項分類の場合、10個の配列で渡される。
10個の中から最大値のインデックスを指定して予測結果とする。
- 二項分類の場合、1つの数字(確率)で渡される。
"""
predictions = model.predict(test_images)
np.argmax(predictions[0])
- 複数の層で構成されるシーケンスモデルを構築する。
- 二項分類のモデルを構築して訓練する。
- 多項分類のモデルを構築して訓練する。
Model作成パターン
二項分類
# 入力の形式は映画レビューで使われている語彙数(10,000語)
vocab_size = 10000
"""
🌟 二項しかないため、0,1をどちらかに割り振って
🌟 sigmoidで0~1の値となるようにする。(おそらく多項分類の二項にしてもいいんじゃないかな?)
"""
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, 16))
model.add(keras.layers.GlobalAveragePooling1D())
model.add(keras.layers.Dense(16, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
"""
🌟 二値分類問題であり、モデルの出力は確率(1ユニットの層とシグモイド活性化関数)の場合、
🌟 binary_crossentropyを使える。
(回帰問題(家屋の値段を推定するとか)の場合、mean_squared_error(平均二乗誤差)を使うこともできる。)
"""
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
多項分類
- 以下のように、出力層を多項数だけ用意し、loss 関数に適切な関数を指定すれば OK
"""
🌟 多項分類のため、出力層を求めるクラスの数だけ出力させ、
🌟 softmaxで0~1の値となるようにする必要がある。
"""
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
"""
🌟 多項分類においてloss関数の評価は多項分の評価にあったものを選ぶ必要がある。
今回の場合、以下などが選ばれる。
sparse_categorical_crossentropy
"""
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
回帰問題
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu',
# tuple or list形式で渡す必要がある。(数字)だとtupleと認識しないので(数字,)とすることで1Dで渡すことができる。
input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
"""
🌟 loss関数にmse(mean_squared_error(平均二乗誤差))を指定することで、評価している。
🌟 metricにはmse,maeとかを選択する。
"""
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
tutorial2
- この章は長いので別ページに分ける
- 事前訓練されたモデルを使用する(転移学習)。
- 事前訓練されたモデルから機能を抽出する。
- モデルへの入力が適切な形状で行われるようにする。
- テストデータをニューラルネットワークの入力の形状に合わせたものにする。
- ニューラル ネットワークの出力データを、テストデータで指定された入力の形状に合わせたものにする。
tutorial3
- データの一括読み込みについて理解している
- コールバックを使用して、訓練サイクルの終了を呼び出す。
- 複数のソースのデータセットを使用する。
- 複数のフォーマット(json や csv など)のデータセットを使用する。
- tf.data.datasets のデータセットを使用する。
データの一括読み込みについて理解している
- 画像の読み込み
- ディレクトリの階層でラベルを分けられたデータを前提に記述する。
import tensorflow as tf
AUTOTUNE = tf.data.experimental.AUTOTUNE # 🌟 別になくてもいい、変数として確保しておいているだけ
import pathlib
# 🌟 flower dataset を使用する。
dataset_url = 'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz'
data_root_orig =
tf.keras.utils.get_file(origin=dataset_url,
fname='flower_photos',
untar=True
)
data_root = pathlib.Path(data_root_orig)
print(data_root)
# 🌟 all_image_pathsにはデータセットの画像のパスが格納される。
all_image_paths = list(data_root.glob('*/*'))
all_image_paths = [str(path) for path in all_image_paths]
import random
random.shuffle(all_image_paths)
# 🌟画像パスのデコード方法
img_raw = tf.io.read_file(img_path) # 🌟この段階ではファイルパスのテンソル
img_tensor = tf.image.decode_image(img_raw) # 🌟 ここで3chの画像にデコードされる
img_final = tf.image.resize(img_tensor, [192, 192]) # リサイズ
img_final = img_final/255.0 # rescale
# --------------------------------------- #
# 🌟関数にまとめるとこんな感じ🌟
def preprocess_image(image):
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [192, 192])
image /= 255.0 # normalize to [0,1] range
return image
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
return preprocess_image(image)
# --------------------------------------- #
# 🌟 以下のようにして使うことで画像を実行時にロードし整形する データセットを作成できる。
# この段階では画像のパスのテンソル
path_ds = tf.data.Dataset.from_tensor_slices(
all_image_paths)
# 🌟ここでパスを画像のテンソルに変換するマップを設定することで、
# 画像のテンソルデータセットとなる。
image_ds = path_ds.map(
load_and_preprocess_image, # 🌟 ここにdecodeする関数を設定する。
num_parallel_calls=AUTOTUNE # 🌟 ここ
)
コールバック
-
EarlyStop の他にも学習率、checkpoint の保存、tensorboard へのアウトプットなどができるコールバックも用意されてる。
# 🌟 コールバックを作る際はこんな感じでCallbackクラスを継承して作成する。
class PrintDot(keras.callbacks.Callback):
# エポックが終わるごとにドットを一つ出力することで進捗を表示
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0: print('')
print('.', end='')
# 🌟🌟 メトリックに改善が見られない場合に終了するコールバック
# patience は改善が見られるかを監視するエポック数を表すパラメーター
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
history = model.fit(
normed_train_data,
train_labels,
epochs=EPOCHS,
validation_split = 0.2,
verbose=0,
callbacks=[early_stop, PrintDot()])
過学習
過学習の対策に以下が有効と言われている。
- 訓練データを増やす(データの改善)
- data 拡張を実行(データの改善)
- dropout 層追加(モデル側の改善策)
- network の容量を減らす(モデル側の改善策)
- 重みの正則化(L1 正則化、L2 正則化などをして過学習を防ぐ)
- バッチ正規化
-
-
訓練データを増やす、data 拡張を実行はほぼ同義なので、まとめて記載する。
- 「訓練データを増やす」 そのままの意味
-
data 拡張を実行 は下記に示す。
-
-
- 訓練時に層から出力された特徴量に対してランダムに「ドロップアウト(つまりゼロ化)」を行うもの
ドロップアウト率は概ね0.2 ~ 0.5が目安と言われている。
# 🌟 使い方 これをモデルの層に追加していくだけ。 keras.layers.Dropout(0.5), - 訓練時に層から出力された特徴量に対してランダムに「ドロップアウト(つまりゼロ化)」を行うもの
-
- パラメータ数が多いと余計な条件に引っかかるようになり、増えすぎることで汎化性能が下がっていく(test データでは高い正解率にも関わらず、validation check にて低いスコアが出てしまう。(過学習))
- セオリーとして小さいモデル、大きいモデルの丁度いいところを探す必要がある。
-
以下に例を示す。
# -------------------------------------------- #
# 🌟 普通のモデル
baseline_model = keras.Sequential([
# `.summary` を見るために`input_shape`が必要
keras.layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),
keras.layers.Dense(16, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
baseline_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
baseline_model.summary()
baseline_history = baseline_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
# -------------------------------------------- #
# 🌟 小さいモデル
smaller_model = keras.Sequential([
keras.layers.Dense(4, activation='relu', input_shape=(NUM_WORDS,)),
keras.layers.Dense(4, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
smaller_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
smaller_model.summary()
smaller_history = smaller_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
# -------------------------------------------- #
# 🌟 大きいモデル
bigger_model = keras.models.Sequential([
keras.layers.Dense(512, activation='relu', input_shape=(NUM_WORDS,)),
keras.layers.Dense(512, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
bigger_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
bigger_model.summary()
bigger_history = bigger_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
# -------------------------------------------- #
# 🌟 大中小のモデルのbinary_crossentropy,epochを表示する関数
def plot_history(histories, key='binary_crossentropy'):
plt.figure(figsize=(16,10))
for name, history in histories:
val = plt.plot(history.epoch, history.history['val_'+key],
'--', label=name.title()+' Val')
plt.plot(history.epoch, history.history[key], color=val[0].get_color(),
label=name.title()+' Train')
plt.xlabel('Epochs')
plt.ylabel(key.replace('_',' ').title())
plt.legend()
plt.xlim([0,max(history.epoch)])
# 🌟モデルのhistryを渡す
plot_history([('baseline', baseline_history),
('smaller', smaller_history),
('bigger', bigger_history)])
-
大、中、小モデルの実行結果
- Baseline と Bigger の train,val が早々に乖離して過学習を起こしていることが分かる。
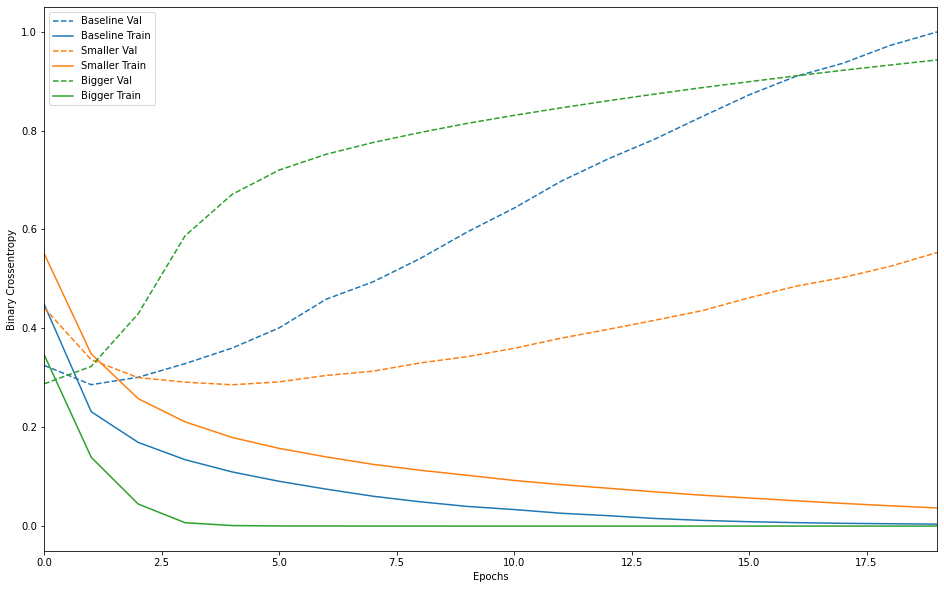
- Baseline と Bigger の train,val が早々に乖離して過学習を起こしていることが分かる。
重みの正則化を加える
- 「単純なモデル」とは、パラメータ値の分布のエントロピーが小さいもの(パラメータの数が少ないもの)です。
したがって、過学習を緩和するための一般的な手法は、重みが小さい値のみをとることで、重み値の分布がより整然となる(正則)様に制約を与えるものです。 -
これを「重みの正則化」と呼ばれ、ネットワークの損失関数に、重みの大きさに関連するコストを加えることで行われます。このコストには 2 つの種類があります。
- L1 正則化 重み係数の絶対値に比例するコストを加える(重みの「L1 ノルム」と呼ばれる)。
- L2 正則化 重み係数の二乗に比例するコストを加える(重み係数の二乗「L2 ノルム」と呼ばれる)。L2 正則化はニューラルネットワーク用語では重み減衰(Weight Decay)と呼ばれる。呼び方が違うので混乱しないように。重み減衰は数学的には L2 正則化と同義である。
- L1 正則化は重みパラメータの一部を 0 にすることでモデルを疎にする効果があります。
-
L2 正則化は重みパラメータにペナルティを加えますがモデルを疎にすることはありません。
- L2 正則化のほうが一般的である理由の一つです。
-
l2(0.001)というのは、層の重み行列の係数全てに対して 0.001x 重み係数の値^2 をネットワークの損失値合計に加えることを意味します。
- このペナルティは訓練時のみに加えられる ため、このネットワークの損失値は、訓練時にはテスト時に比べて大きくなることに注意してください
l2_model = keras.models.Sequential([
keras.layers.Dense(16,
# 🌟 パラメタに l2を指定することで正規化を行う
kernel_regularizer=keras.regularizers.l2(0.001),
activation='relu', input_shape=(NUM_WORDS,)),
keras.layers.Dense(16,
kernel_regularizer=keras.regularizers.l2(0.001),
activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])